


Blog DataBird
>
Data Analytics>
>
Big Data : Qu'est ce que le Big Data en 2025 ? Comment l'IA bouscule les codes ?Big Data : Qu'est ce que le Big Data en 2025 ? Comment l'IA bouscule les codes ?
Big Data. Un mot qui revient à la bouche de tout ceux qui touchent de près ou de loin à la Data. Mais qu'est ce que c'est exactement ? Voyons cela ensemble, et explorons comment l'IA bouscule les codes.

Big Data, difficile d’échapper à cette notion clé de la data analyse...
Ce concept peut sembler bien mystérieux au lecteur novice. Pourtant, ses applications se cachent dans tous les recoins de notre quotidien, et c'est finalement, un concept assez simple aujourd'hui.
C’est le Big Data qui permet de vous proposer de bonnes recommandations de vidéo sur YouTube, qui vous offre la meilleure expérience utilisateur ou consommateur, qui fait avancer la santé, la science, l’industrie…
Alors voyons ensemble ce qu'est le Big Data en 2025, comment l'IA redéfini les codes du big data et comment nous envisageons la chose dans notre formation pour Data Analyst.
Définition : C’est quoi le Big Data ?
Le Big Data, ou données massives en français, désigne de gros volumes de données collectées fréquemment par les entreprises et issues de sources variées. Ces données, lorsqu’elles sont exploitées judicieusement, sont la source d’une très grande richesse.
L’un des meilleurs exemples du Big Data est l’utilisation qu’en font les géants du web comme Amazon et Netflix. En traçant les faits et gestes de leurs utilisateurs et en documentant exhaustivement leurs produits, ils ont pu mettre en place un système de recommandation personnalisé à chacun des utilisateurs.
Grâce à ce système bien rodé, les consommateurs d’Amazon ajoutent des produits recommandés à leur panier et l’audience de Netflix reste fidèle à la plateforme. Ces deux exemples démontrent qu’à partir d’une base de données immense, une entreprise peut dégager un avantage stratégique visant à augmenter ses revenus.
{{formation-data-analyse="/brouillon"}}
Un peu de théorie sur le Big Data : les 5 V du big data
Initialement, on désigne comme « Big Data » les bases de données qui se caractérisent par trois critères : volume, vélocité et variété. Plus récemment (le terme Big Data ayant été inventé en 1997), la définition a été précisée en ajoutant 2 autres « V » : véracité et valeur.
Volume
Le volume est le principal attribut des big data. L’une des premières définitions que l’on donnait au Big Data était que les données étaient trop lourdes pour être traitées sur un ordinateur personnel. Désormais en ligne sur le cloud, l’espace de stockage toujours plus important que les entreprises ont à leur disposition est un atout pour leurs politiques data driven.
Vélocité
Le critère de vélocité désigne la temporalité de la collecte de données. La collecte fréquente de nouvelles données se justifie, d’une part, par l'apparition régulière de nouvelles sources de données ; et d’autre part, par la nécessaire mise à jour des bases de données existantes.
Ainsi, le Big Data évolue à haute fréquence. La collecte des données peut avoir un rythme plus ou moins soutenu, mensuel, hebdomadaire, journalier ou même plusieurs fois par jour.
Variété
Les données dont dispose une entreprise sont rarement issues d’une seule source et ne sont pas toutes du même type. Cette variété fait la richesse du Big Data : formats tabulaires, données temporelles, textuelles, géographiques, photos, vidéos, enregistrements audio, issus du web, provenant de sites en open source ou collectés par les outils propres de l’entreprise…
Véracité
Il faut être très consciencieux dans la vérification de la qualité et l’exactitude des données utilisées. La véracité reflète le niveau de confiance que l’on peut avoir en ces données. Cette question se pose au fur et à mesure que les entreprises basent progressivement leurs stratégies et décisions sur ces bases de données.
Valeur
Pour éviter de trop accumuler de données, il faut se demander quelle est la valeur ajoutée des nouvelles données que l’on collecte ou que l’on produit. En effet, cela représente un coût pour les entreprises : location de l’espace de mémoire en ligne, salaires des personnes chargées de leur gestion (Data Engineer) ou de leur analyse (Data Analyst)…
Les différents métiers de la data et leur usage du Big Data
Le domaine de la data ne cesse de se développer grâce à l’explosion des volumes de données disponibles et à l’essor de la technologie. Chaque métier de cet écosystème intervient à un stade différent de la chaîne de valeur, qu’il s’agisse du stockage, de l’analyse ou de la création de modèles prédictifs.
Voici les principales fonctions que l’on retrouve aujourd’hui :
Le Data Analyst (Analyse, PowerBi, Dashboarding..)
Le Data Analyst est chargé d’extraire et d’interpréter les données afin de produire des analyses exploitables pour l’entreprise.
Grâce à des outils de visualisation et des techniques statistiques, il transforme des volumes massifs d’informations (Big Data) en indicateurs concrets.
Ses résultats aident les décideurs à mieux comprendre leur marché, à identifier des tendances et à formuler des recommandations. On appelle cela, la business intelligence (ou BI).
Le Data Scientist (LLM, Forecasting, Machine Learning..)
Le Data Scientist est un profil très recherché, car il combine des compétences avancées en statistique, en programmation et en mathématiques.
Son travail consiste à modéliser et prédire des comportements ou des événements, en appliquant des méthodes de machine learning ou de deep learning.
Le Data Scientist crée des algorithmes qui exploitent la puissance du Big Data pour repérer des motifs complexes et apporter des solutions innovantes.
Le Data Engineer (Pipeline, Data Quality...)
Chargé de la conception et de l’optimisation des infrastructures de données, le Data Engineer construit les pipelines qui permettent de collecter, stocker, traiter et distribuer des données à grande échelle.
Il veille à ce que les plateformes Big Data (telles que Hadoop, Spark ou des bases de données NoSQL) fonctionnent de manière fluide et efficace, pour alimenter l’ensemble de l’écosystème data.
Le Data Architect (Architecture de données, Schémas..)
Le Data Architect définit l’architecture globale de la gestion de données. Il conçoit les structures et les schémas qui permettront aux applications Big Data de fonctionner de façon cohérente et scalable.
Son rôle est essentiel pour garantir la qualité, l’intégrité et la sécurité des données, tout en anticipant les besoins futurs de l’entreprise.
Machine Learning Engineer
Proche du Data Scientist, le Machine Learning Engineer est spécialisé dans la mise en place et l’optimisation d’algorithmes de machine learning en production.
Il s’assure que les modèles développés peuvent gérer des flux de données massifs et répondre rapidement aux besoins de l’entreprise (analyse en temps réel, personnalisation de l’expérience client, etc.).
Analytic Engineer
Positionné à la frontière entre le Data Engineer et le Data Analyst, l’Analytic Engineer se spécialise dans la transformation, la modélisation et la préparation des données pour un usage analytique.
Il met en place des structures de données faciles à exploiter, crée des modèles et des vues adaptées aux besoins métier, et s’assure que les équipes d’analyse disposent de données fiables et à jour.
Son rôle est clé pour accélérer les processus de prise de décision et faciliter l’automatisation de la Business Intelligence.
Quelles sont les principales technologies et outils utilisés pour traiter les données du Big Data ?
Le Big Data repose sur des volumes de données gigantesques qu’il faut savoir collecter, stocker et analyser de manière efficace. Plusieurs technologies et outils se distinguent pour leur rôle essentiel dans ces différentes étapes. Voici un tour d’horizon de ceux qui sont les plus utilisés aujourd’hui :
1. SQL : la base indispensable
SQL (Structured Query Language) est le langage de requête par excellence pour interagir avec les bases de données relationnelles. Il permet, via une syntaxe proche du langage naturel, de réaliser une multitude d’actions :
- Créer ou supprimer des tables
- Faire des jointures entre plusieurs sources de données
- Regrouper et filtrer des informations
- Effectuer des opérations mathématiques et statistiques
Indispensable pour quiconque souhaite manipuler de grandes quantités de données, la maîtrise de SQL est un atout précieux sur le marché de l’emploi. Pour ceux qui souhaitent acquérir ces compétences rapidement, la formation SQL de DataBird permet de se former en six semaines, sans prérequis techniques. Éligible au CPF, elle associe l’avantage d’un apprentissage à distance et la pratique intensive, afin d’obtenir une maîtrise opérationnelle du langage.
2. Python : l’incontournable pour l’analyse et la Data Science
Au-delà du SQL, Python s’impose comme l’un des langages de programmation phares dans le domaine de la data. Grâce à sa simplicité de syntaxe et son écosystème riche de bibliothèques (comme Pandas, NumPy, Scikit-learn ou encore Matplotlib), Python permet de :
- Manipuler de grandes quantités de données
- Développer des modèles statistiques et de machine learning
- Construire des visualisations pour mieux comprendre et communiquer les résultats
Il est devenu le langage favori des Data Scientists et Data Analysts en raison de sa grande polyvalence et de sa large communauté d’utilisateurs.
3. Power BI : la solution de Business Intelligence par Microsoft
Power BI, développé par Microsoft, est un outil de Business Intelligence qui permet de créer rapidement des tableaux de bord et des rapports visuels à partir de différentes sources de données. Ses principales forces sont :
- Une interface conviviale et intuitive
- Des connecteurs permettant de relier Power BI à la plupart des bases de données et applications métier
- Des fonctionnalités d’exploration et de collaboration en temps réel
Cette solution s’avère particulièrement adaptée aux petites et moyennes entreprises qui souhaitent déployer rapidement une plateforme de reporting et de visualisation sans investir dans des infrastructures lourdes.
4. Excel & Google Sheet : des outils classiques toujours d’actualité
Bien qu’ils soient plus anciens et moins spécialisés dans le Big Data que d’autres solutions, Excel et Google Sheet restent incontournables dans de nombreuses entreprises. Ils s’utilisent pour :
- Réaliser des analyses rapides de données de taille modérée
- Créer des tableaux de suivi et des formules simples
- Collaborer en ligne (notamment sur Google Sheet) pour partager des feuilles de calcul en temps réel
Malgré leurs limites face à des volumes de données très importants, ces outils sont souvent les premiers adoptés par les équipes métiers et demeurent utiles pour des analyses basiques ou un prototypage rapide.
5. Looker Studio : la plateforme de reporting et de visualisation de Google
Anciennement appelé Data Studio, Looker Studio est l’outil de reporting et de visualisation proposé par Google. En se connectant aisément aux solutions du Google Marketing Platform (Google Analytics, Google Ads, etc.) ou à d’autres bases de données, Looker Studio permet :
- De créer des tableaux de bord web en quelques clics
- De partager facilement les rapports avec des équipes multiples
- D’exploiter un grand choix de connecteurs et de modèles préconçus
Particulièrement adapté pour le suivi marketing ou la mise en place d’analyses web, Looker Studio se révèle un choix intéressant pour quiconque souhaite un outil léger, accessible et très visuel.
6. En 2025 : l’IA, la nouvelle ère du Big Data
Alors que nous nous projetons vers 2025, l’Intelligence Artificielle (IA) s’impose de plus en plus comme un pilier incontournable du Big Data. Les avancées technologiques en deep learning, en NLP (Natural Language Processing) ou en vision par ordinateur transforment la façon dont nous exploitons les données. Les entreprises se tournent vers :
- L’automatisation poussée : détection d’anomalies en temps réel, prédiction de pannes, optimisation d’itinéraires, etc.
- La personnalisation : recommandations de produits, ciblage publicitaire affinée, services clients automatisés plus intelligents.
- La démocratisation de l’IA : de plus en plus d’outils et de plateformes no code/low code rendent l’IA accessible à un plus grand nombre de professionnels et de métiers.
Protection des données et Big Data : Un enjeux de cybersécurité et de RGPD !
L’utilisation de gros volumes de données par une entreprise pose la question de la sécurité des données. On distingue les données à caractère personnel (DCP) des autres données.
Les DCP permettent d’identifier directement une personne physique. Depuis quelques années, ces données sont protégées en Europe par le Règlement Général sur la Protection des Données (RGPD), qui définit le cadre juridique de l’utilisation de données à caractère personnel avec des règles précises et contraignantes.
Les entreprises qui souhaitent utiliser des DCP sont notamment tenues au principe de finalité qui vérifie l’intérêt légitime, légal et précis de l’utilisation des DCP. Elles doivent aussi garantir la sécurité des données, le consentement des personnes concernées et leur accès à leurs propres informations.
Le RGPD définit le principe de Privacy by Design, qui implique que les entreprises doivent songer à la protection des données dès la conception du projet, au travers d’un bilan des risques encourus. Ainsi, l’entreprise respecte le RGPD à chaque étape et interroge continuellement la pertinence des DCP (ce qui limite leur collecte).
Le RGPD ne concerne pas les données non personnelles. Cependant, les données étant très précieuses et concurrentielles pour les entreprises, elles ont tout intérêt à en assurer la sécurité.

Comment l'IA bouscule de le Big Data en 2025 ?
Alors que l’écosystème Big Data continue de s’étendre, l’Intelligence Artificielle (IA) s’impose comme un catalyseur majeur, comme nous le détaillons dans notre guide des tendances IA 2025.
En 2025, l’IA n’est plus seulement un sujet de recherche : elle est devenue une réalité opérationnelle pour les entreprises de toutes tailles, façonnant une nouvelle ère où la donnée est exploitée de manière plus intelligente, plus automatisée et plus proactive.
1. Des modèles plus puissants grâce à des volumes de données colossaux
L’IA se nourrit de données, et les volumes croissants du Big Data permettent de développer et d’entraîner des modèles bien plus sophistiqués. Que ce soit dans le traitement automatique du langage (NLP), la reconnaissance d’images ou le machine learning prédictif, la qualité et la quantité de données jouent un rôle crucial pour :
- Améliorer la précision des prédictions
- Dégager des tendances plus fines, difficiles à détecter par des méthodes traditionnelles
- Accélérer la capacité à déployer des services et produits innovants
Avec la montée en puissance des infrastructures cloud, ces volumes gigantesques de données peuvent être centralisés et analysés plus rapidement, à des coûts de plus en plus compétitifs.
2. L’automatisation, clé de la compétitivité
En 2025, on assiste à une automatisation croissante des processus. Les tâches répétitives et chronophages, comme le nettoyage et la préparation des données ou la détection d’anomalies, sont désormais confiées à des algorithmes d’IA. Résultat :
- Les équipes data se concentrent sur des missions à forte valeur ajoutée (analyse poussée, stratégie, créativité)
- Les entreprises gagnent en efficacité et en réactivité, s’adaptant plus rapidement aux fluctuations du marché
- Les risques liés aux erreurs manuelles sont nettement réduits
Cette automatisation contribue à diminuer la barrière d’entrée de la data, permettant à un plus grand nombre d’acteurs de bénéficier du potentiel du Big Data sans mobiliser d’immenses ressources techniques.
3. L’émergence de l’IA “expliquable” et responsable
Face à la multiplication des modèles d’IA, la question de la transparence et de la responsabilisation devient centrale. En 2025, les entreprises et les régulateurs accordent une attention particulière à l’Explainable AI (XAI), qui vise à rendre les algorithmes plus compréhensibles pour les utilisateurs finaux. L’objectif est multiple :
- Éviter la “boîte noire” des systèmes de deep learning
- Identifier et limiter les biais potentiels dans les données et les prédictions
- Se conformer aux réglementations de plus en plus strictes en matière de confidentialité et de protection des données
Cette évolution va de pair avec une sensibilisation grandissante des consommateurs et des citoyens, soucieux de savoir comment leurs données sont exploitées et à quelles fins.
4. La démocratisation de la Data Science grâce au no code/low code
En 2025, les plateformes no code/low code se sont imposées comme des outils indispensables pour les professionnels souhaitant développer des applications d’IA sans devoir maîtriser en détail la programmation ou le deep learning. Grâce à ces interfaces graphiques et à des modèles pré-entraînés :
- De nombreux métiers (marketing, finance, logistique…) s’approprient l’IA et l’intègrent à leurs process
- Les délais de mise sur le marché des innovations se raccourcissent, dopant la compétitivité
- Les experts data peuvent se focaliser sur des projets plus complexes, laissant la partie “basique” de l’IA à des utilisat
- eurs métiers formés aux outils no code/low code
Cette démocratisation de l’IA accélère l’adoption de technologies avancées dans des domaines jusqu’ici réservés à une élite technique.
5. De la prédiction à la prescription et à la personnalisation
Autre changement majeur : la maturité des modèles de machine learning fait passer le Big Data d’une logique de prédiction à une logique de prescription. Les systèmes basés sur l’IA ne se contentent plus d’anticiper un besoin ou une action future :
- Ils sont capables de recommander les meilleures solutions à un problème identifié
- Ils s’adaptent automatiquement aux préférences ou au comportement d’un client (personnalisation)
- Ils génèrent des insights stratégiques de plus en plus précis, guidant la prise de décision dans des domaines variés (supply chain, santé, services financiers, etc.)
Dans ce contexte, les entreprises peuvent proposer des expériences sur-mesure à leurs clients ou usagers, augmentant significativement leur satisfaction et leur fidélisation.
{{formation-data-analyse="/brouillon"}}
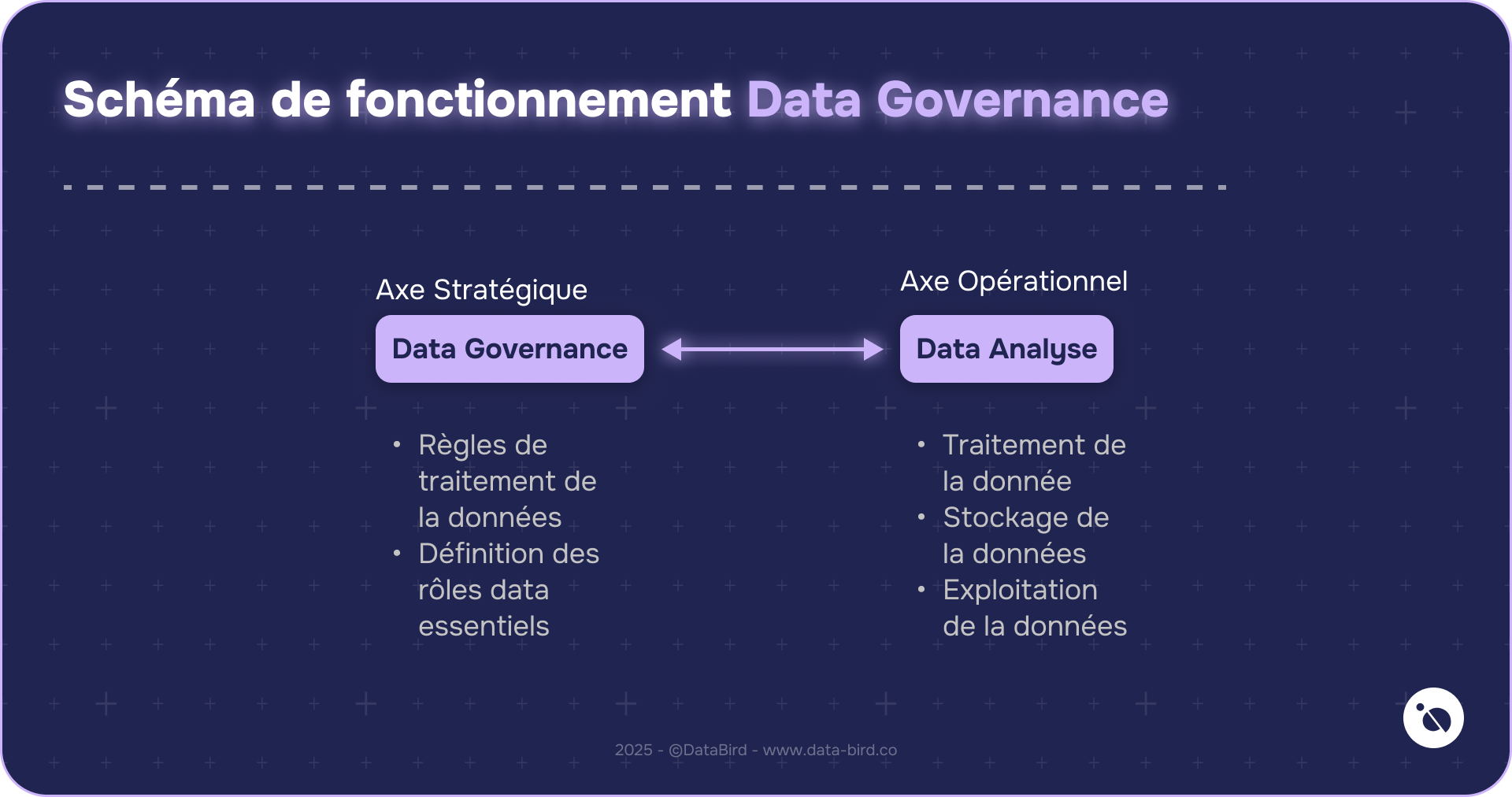
Data Governance & Big Data : Une relation compliquée
Quand on parle de Big Data, on imagine souvent d’énormes quantités d’informations que l’on traite à toute vitesse pour en tirer des insights. Pourtant, sans une gouvernance des données solide, ces montagnes de données peuvent vite tourner au cauchemar. Pourquoi ? Parce qu’il ne suffit pas de tout stocker, il faut aussi s’assurer de la qualité, de la sécurité et du respect de la vie privée.
À mesure que les entreprises collectent toujours plus de données, elles se retrouvent confrontées à des questions délicates : Qui a accès à quoi ? Comment garantir que les données sont fiables ? Comment respecter la réglementation en vigueur ? Sans une Data Governance fiable, les données ne pourront pas être traitées !
Visualiser le Big Data : Utiliser la Data Visualisation pour voir nos datas
Quand on manipule d’immenses volumes de données, il est presque impossible d’y repérer les tendances et les signaux clés sans un coup de pouce visuel.
La Data Visualisation traduit ces masses d’informations en graphiques, tableaux de bord et cartes interactives, permettant de saisir en un coup d’œil ce qui se passe vraiment.
Avec des outils de data visualisation comme Power BI ou Tableau, on identifie plus facilement les schémas, les anomalies ou les opportunités, rendant la prise de décision plus rapide et plus éclairée. En bref, la Data Visualisation donne vie au Big Data et le rend enfin accessible à tous.
Comment la business intelligence intéragit avec le Big Data ?
La business intelligence (BI) est un ensemble de méthodes et d’outils qui visent à transformer des données brutes en informations exploitables pour les équipes métier.
Avec le Big Data, la BI change d’échelle : elle ne se limite plus aux données traditionnelles (CRM, ERP, etc.), mais s’appuie aussi sur des volumes massifs et variés (réseaux sociaux, IoT, logs, etc.).
Les plateformes et les applications de BI (comme Power BI ou Looker Studio) doivent désormais être capables de se connecter à des écosystèmes data plus complexes, souvent répartis dans le cloud.
Ainsi, la BI et le Big Data forment un duo gagnant : l’un structure et traite d’énormes quantités de données, l’autre les traduit en tableaux de bord et rapports actionnables, pour éclairer et accélérer la prise de décision.

Faites un premier pas dans la data avec nos cours gratuits
Démarrer
Les derniers articles sur ce sujet

Mis à jour le
12/3/2025
Data Owner : Comprendre ce métier clé de la gouvernance des données

Mis à jour le
11/3/2025
Devenir Data Driven : Comment devenir une organisation Data Driven ?

Difficulté :
Facile